
hello world
AWS DynamoDB 본문
DynamoDB란?
- AWS에서 제공하는서버리스 기반 key-value NoSql 데이터베이스입니다.
- Key-Value 데이터베이스이다.
-NoSQL database 관계형 데이터베이스가 아님
-엄청난 작업량으로 스케일링하고 완전히 분산되어있음
-빠르고 일관적인 서비스
- DBMS처럼 트랜잭션, JOIN 과 같은 복잡한 테이블 데이터 처리과정이 있는 경우에는 비적합
Traditional Architecture
-RDBMS를 사용한다
-SQL 쿼리 언어를 사용한다.
-sum, 집합, 복합한 계산을 할 수 있다.
NoSQL databases
-쿼리 연결을 지원하지 않음 제한이없음
-sum, 집합, 복합한 계산을 할 수 없다
-수평적으로 확장된다
DynamoDB - Basic
-테이블로 이루어져있다
-각각의 테이블은 Primary Key(기본키) 를 갖는다
-테이블마다 아이템이라고 하는 행을 무한대로 생성할 수 있다.
-각 item은 속성을 갖는다.
DynamoDB - Primary Keys
-option 1 : partition key(Hash) 파티션키(해쉬전략)
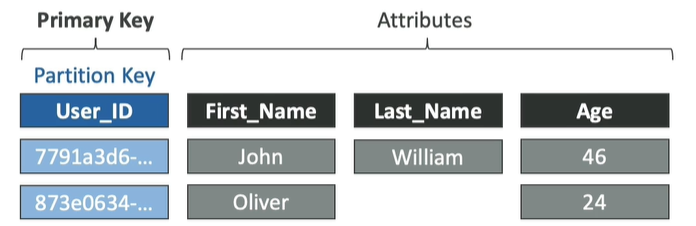
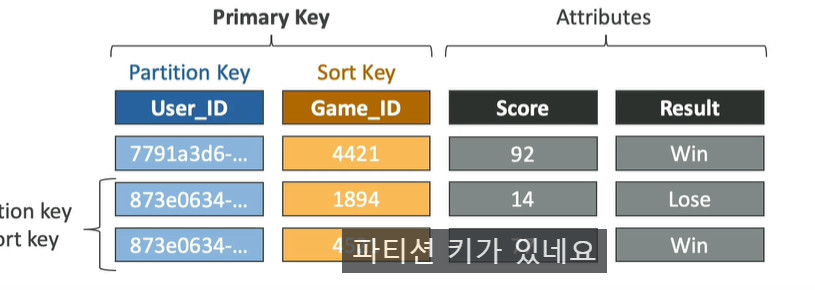
-option 2: Partition Key + Sort Key (Hash + Range)
파티션키에 의해 데이터가 그룹화됨 (동일한 partition Key 가능)
DynamoDB - Read/Write 모드
- 테이블 용량을 제어하는 방법
1) Provisioned Mode (프로비저닝모드) (default)
- 트래픽의 양이 일정하거나 점진적으로 변경되는 경우 사용한다.
- 비용관리를 위해 용량 요구 사항을 예측할 수 있는 경우 사용한다.
- 어플리케이션에 필요한 초당 읽기 및 쓰기 횟수를 지정한다.
- 용량을 미리 계획해야한다.
- 오토 스케일링을 사용하여 트래픽 변경에 따라 프로비저닝된 용량을 자동으로 조정할 수 있다.
- 프로비저닝 될 것에 대한 비용을 지불해야한다.
- Read Capacity Units (RCU) - 읽기를 위한 처리량
- Write Capacity Units (RCU) - 쓰기를 위한 처리량
2) On-Demand Mode(온디맨드 모드)
- 트래픽을 예측할 수 없는 경우 사용한다.
- 자동적으로 작업에 기반해 읽기와 쓰기(Read,Write) 규모의 업 다운을 갖는다.
- 용량을 미리 계획할 필요가 없다
- 많은 트래픽이 발생할 수록 이전에 도달한 최대 트래픽 수준까지 확장된다.
- 만약 이전에 도달한 최대 트래픽을 넘는다면 이전의 2배에 해당하는 크기로 자동조정된다.
- Provisioned Mode 보다 훨씬 비싸다. 사용한 만큼만 가격을 지불한다.
secondary index(보조인덱스)
보조 인덱스를 사용하는 주요 목적은 데이터 액세스 성능을 향상시키는 것
secondary Index란 대체키와 테이블의 다른 attr들의 subset을 포함하는 데이터 구조이다.
테이블과 마찬가지로 index에 쿼리를 더해서 데이터를 가져올수있다.
secondary index종류
1) GSI (Global secondary index)
- pk와 sk가 base table의 key들과 달라도 됩니다.
- base table과 따로 scale 됩니다.
- 테이블이 생성된 후에 추가되거나 수정될 수 있다.
1) LSI (Local secondary index)
- base table과 같은 partition key, 다른 sort key를 사용합니다.
- partition key에 해당하는 하나의 partition에 대해서만 쿼리하기 때문에 local이라고 부릅니다.
Accelerator (DAX)
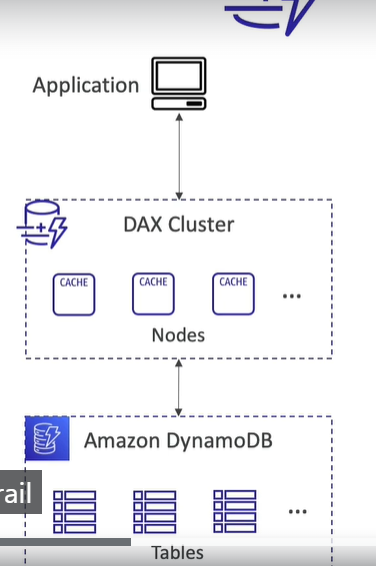
- DynamoDB를 위한 완벽하게 관리되고 가용성이 뛰어난 원활한 메모리 내 캐시다.
- 캐싱을 통해 읽기 혼잡을 해결할 수 있다.
- 캐시된 데이터에 대한 MS 단위의 대기시간을 보장한다
- Multi -AZ 같은 설정을 하는 것이 좋다
Accelerator (DAX) vs ElastiCache
둘다 데이터 베이스 쿼리 결과를 캐싱하여 빠른 데이터 결과를 제공한다는 공통점을 갖는다.
가장 큰 차이점은 DAX는 DB 결과 각각의 오브젝트를 캐싱하고, Elasticache는 집약된 결과를 캐싱한다.
- 동시 백만 개 요청 이상의 환경에서도 마이크로초 성능의 응답이 필요 -> DAX
- DynamoDB의 읽기(READ) 성능을 향상하기 위한 옵션 -> DAX
- 애플리케이션 구조의 변화를 최소화하면서 DynamoDB의 응답 성능 향상 -> DAX
- 요금 최적화를 고려하여 단순히 DB 캐싱 레이어 추가 -> ElastiCache
- 기존 On-Prem 환경의 Redis, Memached 서비스 마이그레이션 -> ElastiCache
- 데이터베이스가 DynamoDB가 아닌 RDS for MySQL, PostgreSQL이라면 당연히 -> ElastiCache
- ElastiCache는 데이터 쿼리 자체를 빠르게 하는 새로운 레이어를 추가하는 것
'자격증 > AWS' 카테고리의 다른 글
| SAA 키워드 정리 (0) | 2024.07.15 |
|---|---|
| AWS SAA(Solution Architect Associate) 정리 (1) | 2024.07.10 |
| AWS CloudFront / CDN(Content Delivery Network) (0) | 2024.07.02 |
| Amazon S3(Simple Storage Service) (0) | 2024.07.01 |
| EC2 (Elastic Compute Cloud) / AMI (Amazone Machine Image) (0) | 2024.07.01 |


